The Dark Knight of Search: Apache Lucene Unmasked - Part 1

The Dark Knight of Search: Apache Lucene Unmasked - Part 1
In the depths of Gotham, a crime wave surges. Information is scattered, and only one hero can make sense of the chaos—Batman. But what if Batman had a digital counterpart? Meet Apache Lucene, the Dark Knight of search technology, designed to bring order to unstructured data. This first part of our series explores the foundational concepts of Lucene, illustrating its power through code examples and analogies.
Why Apache Lucene?
Just as Batman relies on his intellect and tools to analyze evidence, Lucene leverages powerful indexing and search capabilities to efficiently process massive amounts of text. It’s the robust engine powering search in applications like Elasticsearch and Solr, significantly impacting how we interact with information today.
How Lucene Works: The Batcomputer Analogy
Imagine Batman in the Batcave. His Batcomputer holds detailed records of every villain in Gotham. Instead of manually searching through every file, he queries "Joker AND heists," and the Batcomputer instantly returns relevant results. Apache Lucene performs similarly, swiftly retrieving relevant documents using an Inverted Index.
A Simple Lucene Search Example (Java)
Let's build a basic Lucene-powered search engine in Java:
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.store.RAMDirectory;
public class BatmanLucene {
public static void main(String[] args) throws Exception {
StandardAnalyzer analyzer = new StandardAnalyzer();
RAMDirectory index = new RAMDirectory();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(index, config);
addDoc(writer, "Joker plans a bank heist");
addDoc(writer, "Batman stops a robbery at Gotham Bank");
writer.close();
Query query = new QueryParser("content", analyzer).parse("Joker AND heist");
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(index));
TopDocs docs = searcher.search(query, 10);
for (ScoreDoc sd : docs.scoreDocs) {
Document d = searcher.doc(sd.doc);
System.out.println("Found: " + d.get("content"));
}
}
private static void addDoc(IndexWriter writer, String value) throws Exception {
Document doc = new Document();
doc.add(new TextField("content", value, Field.Store.YES));
writer.addDocument(doc);
}
}
This program indexes and searches "case files," demonstrating Lucene's core functionality.
The Detective's Notebook: Understanding Inverted Indexes
Imagine Batman's meticulously organized records. An inverted index is a data structure that mirrors this organization. Instead of sequentially searching documents, it maps words to the documents containing them, enabling incredibly fast lookups. This is fundamentally how Lucene achieves its speed and efficiency.
How an Inverted Index Works
A traditional database requires scanning each record. An inverted index reverses this, organizing words and mapping them to documents. This dramatically reduces search time.
Inverted Index Example
Consider these crime reports:
- The Joker robbed Gotham Bank.
- The Riddler left a riddle at Gotham Bank.
- Penguin’s henchmen were seen at Gotham Docks.
Lucene would create an inverted index similar to this:
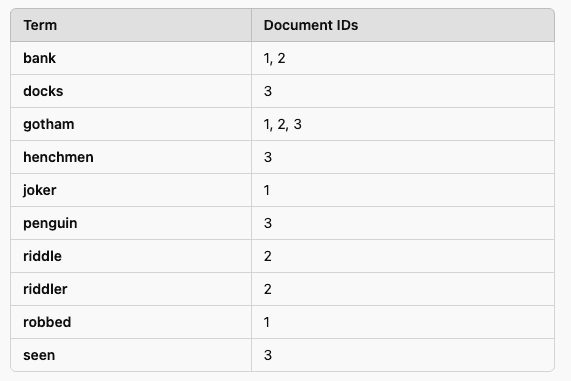
Searching for "Gotham Bank" instantly returns documents 1 and 2.
Tokenization: Deciphering the Villain's Message
Before indexing, Lucene tokenizes text, breaking it into keywords. This process, similar to Batman deciphering codes, improves search accuracy. For example, "The Joker robbed Gotham Bank" becomes: `joker`, `robbed`, `gotham`, `bank`. Common words (stop words) like "the" are often ignored.
Stemming and Lemmatization: Recognizing Word Variations
Lucene uses stemming and lemmatization to group related words. Stemming reduces words to their root (e.g., "running" → "run"), while lemmatization converts words to their dictionary form (e.g., "better" → "good"). This ensures that searches for "robbed" also return results containing "robbery".
Indexing Documents (Java)
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.store.RAMDirectory;
public class BatcomputerIndex {
public static void main(String[] args) throws Exception {
RAMDirectory index = new RAMDirectory();
IndexWriterConfig config = new IndexWriterConfig(new StandardAnalyzer());
IndexWriter writer = new IndexWriter(index, config);
addDocument(writer, "The Joker robbed Gotham Bank.");
addDocument(writer, "The Riddler left a riddle at Gotham Bank.");
addDocument(writer, "Penguin’s henchmen were seen at Gotham Docks.");
writer.close();
System.out.println("Index built successfully. The Batcomputer is ready!");
}
private static void addDocument(IndexWriter writer, String content) throws Exception {
Document doc = new Document();
doc.add(new TextField("content", content, Field.Store.YES));
writer.addDocument(doc);
}
}
This code creates the inverted index, mapping words to documents for efficient searching.
Conclusion: The Batcomputer is Ready!
Apache Lucene, like the Batcomputer, empowers applications with incredibly fast and efficient search capabilities. By understanding the underlying principles of inverted indexes, tokenization, and stemming/lemmatization, developers can harness Lucene's power to build robust and responsive search solutions. In the next part, we'll delve into Lucene's query capabilities.
Related Articles
Software Development
Unveiling the Haiku License: A Fair Code Revolution
Dive into the innovative Haiku License, a game-changer in open-source licensing that balances open access with fair compensation for developers. Learn about its features, challenges, and potential to reshape the software development landscape. Explore now!
Read MoreSoftware Development
Leetcode - 1. Two Sum
Master LeetCode's Two Sum problem! Learn two efficient JavaScript solutions: the optimal hash map approach and a practical two-pointer technique. Improve your coding skills today!
Read MoreBusiness, Software Development
The Future of Digital Credentials in 2025: Trends, Challenges, and Opportunities
Digital credentials are transforming industries in 2025! Learn about blockchain's role, industry adoption trends, privacy enhancements, and the challenges and opportunities shaping this exciting field. Discover how AI and emerging technologies are revolutionizing identity verification and workforce management. Explore the future of digital credentials today!
Read More


